Coding Agents and Operational Safety
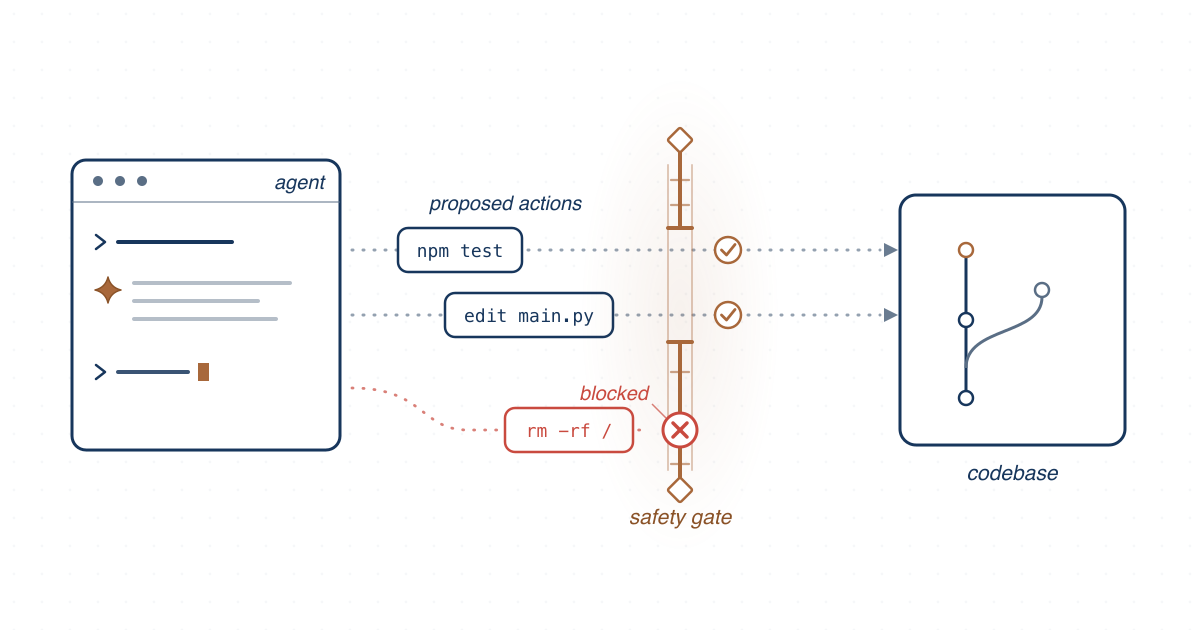
We study how autonomous coding agents fail during ordinary development work and design safeguards, from constraint enforcement to failure transparency and safe-halt behaviors, for deploying them responsibly.
People: Sumon Biswas, Alif Al Hasan, David O'Brien, Sayem Imtiaz, Rabe Abdalkareem, Emad Shihab, Hridesh Rajan
Overview
Autonomous coding agents built on large language models are wired directly into development workflows: they edit files, run commands, configure environments, and fix bugs with growing autonomy. Most safety evaluations of these tools focus on explicitly malicious prompts, but we argue this misses the larger and more common danger: agents that fail during ordinary, goal-directed work through destructive operations, constraint violations, authorization bypasses, and silent errors that surface only after damage is done.
We characterize these operational risks empirically, build taxonomies and benchmarks grounded in real usage, and translate the findings into concrete safeguards. This connects our recent work on agentic-code safety, appearing at ASE 2026, with earlier work on AI-assisted technical-debt maintenance at ICSE 2024, and asks how to measure agent safety as capabilities grow and how to give developers meaningful oversight of systems acting on their behalf.
Current Focus
- An incident-driven study of what breaks when LLMs code (ASE 2026): triangulating 68,816 screened papers across 22 premier venues with 16,586 GitHub issues from deployed LLM-powered coding tools, we confirm 547 genuine safety failures and derive a taxonomy of 33 operational risk types across seven dimensions.
- Everyday development, not adversarial input, is where most harm occurs: over 65% of incidents arise during routine bug fixing and setup or configuration, and 326 of the 547 incidents are rated high or critical severity.
- Safeguards that go beyond adversarial-prompt defenses: environmental constraint enforcement, failure transparency, and safe-halt capabilities that let an agent stop rather than push forward into harm.
- How maintenance context shapes generated code: our ICSE 2024 study of 36,381 TODO comments from 102,424 repositories and 1,140 Copilot-generated code bodies shows that Copilot both reproduces the symptoms of self-admitted technical debt and can repay it under the right prompting.
Related Publications