Causal Fairness in Machine Learning Pipelines
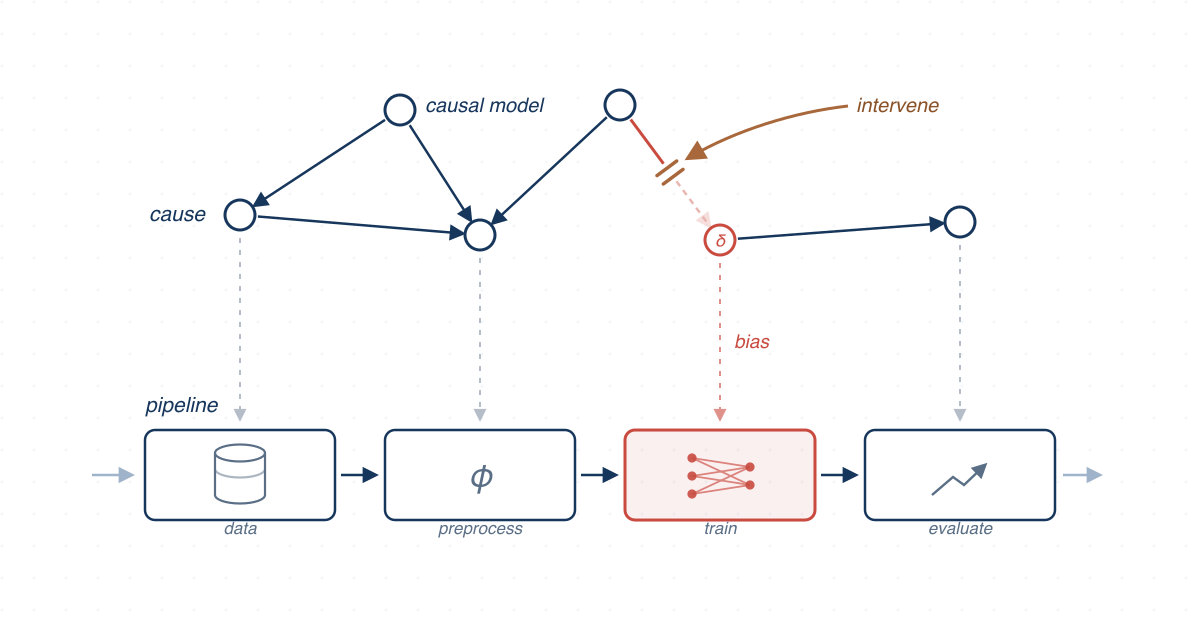
We used causal reasoning to measure the fairness of individual stages in machine learning pipelines and studied how fairness composes across preprocessing, ensembles, and real-world models.
People: Sumon Biswas, Usman Gohar, Hridesh Rajan
Overview
Most fairness research treated a machine learning model as a single black box, measuring bias only from its final predictions. Real pipelines, however, contain an ordered set of components — data filtering, imputation, encoding, feature transformation, training, tuning — and each can affect the fairness of the resulting model. We investigated fairness at the component level: using causal reasoning, we intervened on one stage at a time, constructed an alternative pipeline without that stage, and measured the resulting prediction disparity to attribute unfairness to specific components.
We grounded this work in real-world models rather than default-configured library classifiers, building benchmarks from Kaggle models, pipelines collected from multiple sources, and ensemble models. Beyond single classifiers, we studied how the local fairness of a stage or a learner composes into the global fairness of the pipeline or ensemble, and showed that this composition can be exploited during development to choose components that offset each other’s bias.
Key Results
- We introduced causal fairness measures for pipeline stages — four metrics based on the prediction disparity between a pipeline and its counterfactual variant with a stage removed — and evaluated 37 pipelines from three sources (FSE 2021). Data filtering, missing-value removal, and feature selection often introduced bias, while feature standardization and non-linear transformers were consistently fair.
- We showed how the local fairness of a preprocessing stage composes into the global fairness of the pipeline, and used this composition to choose downstream transformers that mitigate unfairness — for example, pairing a stage that favors the privileged group with one that favors the unprivileged group.
- In an empirical study of 40 top-rated Kaggle models across 5 tasks with 7 mitigation techniques (FSE 2020), we found that some model optimization techniques induce unfairness, that library fairness-control mechanisms are undocumented, and that preprocessing mitigation is usually preferable because post-processing consistently costs accuracy and F1 score.
- Using a benchmark of 168 ensemble models (bagging, boosting, stacking, and voting) on four fairness datasets (ICSE 2023), we showed that fair learners can still produce an unfair ensemble, that ensembles can be designed to be fairer without applying mitigation techniques, and that the interplay between fairness composition and data characteristics can guide fair ensemble design.
Related Publications
- Fair Preprocessing: Towards Understanding Compositional Fairness of Data Transformers in Machine Learning Pipeline FSE 2021
- Towards Understanding Fairness and its Composition in Ensemble Machine Learning ICSE 2023
- Do the Machine Learning Models on a Crowd Sourced Platform Exhibit Bias? An Empirical Study on Model Fairness FSE 2020