Trustworthy LLMs and VLMs
Testing and analysis for hidden failure modes in large language and vision-language models, from social bias under black-box access to reasoning-level backdoors.
People: Sumon Biswas, Towsif Raiyan, Zhihao Dou, Qinjian Zhao, Zhiqiang Gao, Sina Salimian, Gias Uddin, Henry Leung
Overview
Large language and vision-language models are deployed in settings where biased, inconsistent, or manipulated behavior can affect users, yet their internals are often unavailable or hard to inspect. We develop methods that expose and characterize such hidden failures, treating trustworthiness as a property that must be tested for rather than assumed — and connecting each testing method to a concrete path for mitigation or defense.
A recurring theme in our work is that trustworthiness must account for a model’s reasoning process, not only its final answer. Attacks and guardrails that operate on outputs alone tend to leave reasoning traces that are inconsistent or easy to flag, but as models increasingly expose their chain-of-thought, the reasoning itself becomes both a new attack surface and a new opportunity for defense. We study how bias and backdoor threats propagate through model behavior, how to characterize them with principled signals, and how to build safeguards that hold up against adaptive adversaries.
Current Focus
- Six metamorphic relations that transform direct bias-inducing prompts into semantically equivalent but adversarially challenging variants, exposing up to 14% more hidden biases than existing tools across six black-box LLMs on the BiasAsker benchmark
- Linking testing to mitigation: fine-tuning with original and MR-mutated samples raises safe response rates from 54.7% to over 88.9% across models
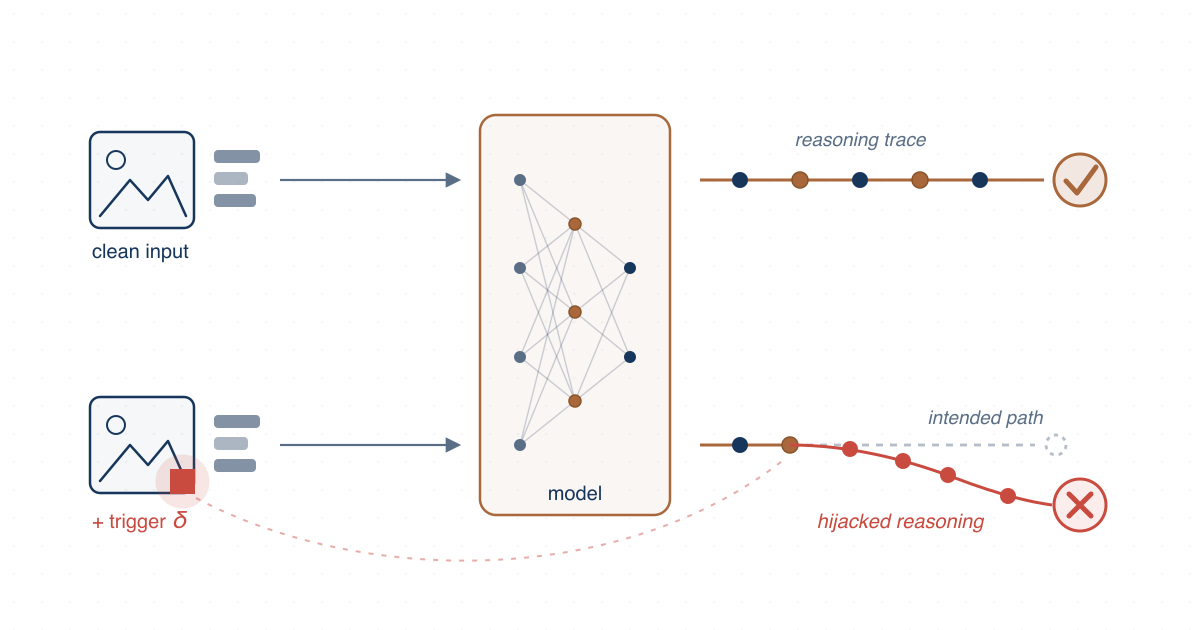
- ReShift (ECCV 2026), the first aha-moment-driven reasoning-level backdoor framework, which redirects a vision-language model’s chain-of-thought while preserving surface coherence via poisoned reasoning-aware data construction and supervised–reinforcement joint optimization
- Entropy Rebound as a principled signal for characterizing reasoning redirection, with theoretical guarantees linking entropy gaps to trajectory-level divergence — groundwork for detectors of reasoning-level manipulation
Related Publications