Large-Scale Mining of Data Science Software
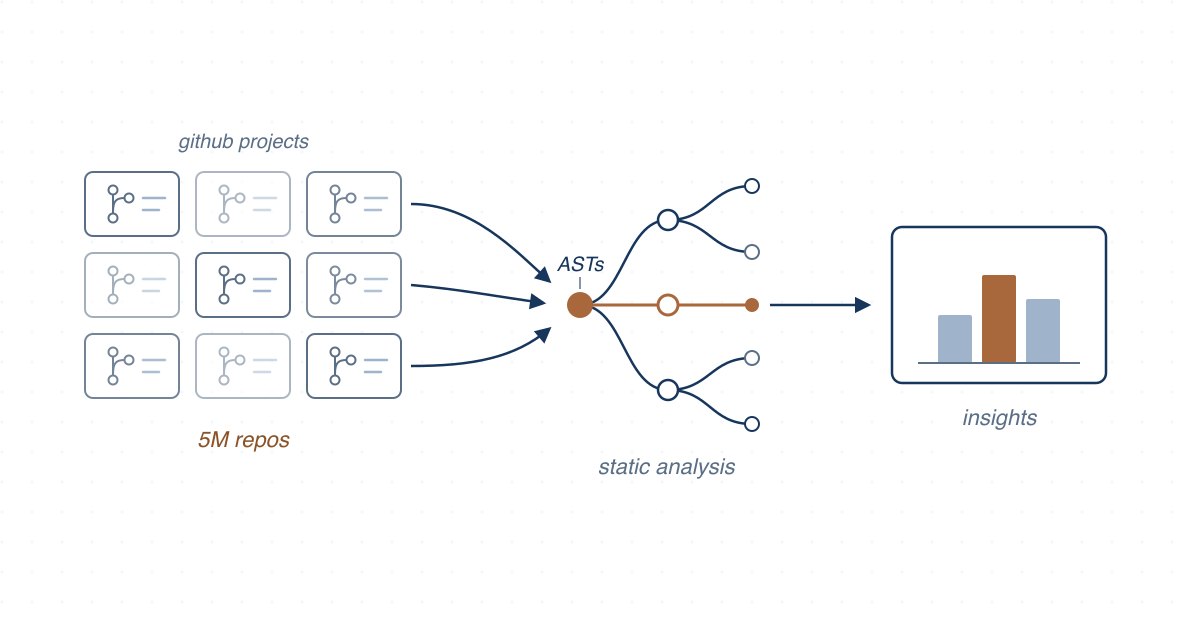
We built infrastructure to mine millions of Python data science programs from GitHub and studied how data science pipelines are structured in theory, in-the-small, and in-the-large.
People: Sumon Biswas, Md Johirul Islam, Yijia Huang, Mohammad Wardat, Hridesh Rajan
Overview
Data science components have become common in software, yet software engineering research on this class of systems needed data and tooling that did not exist. We built an infrastructure to mine data science software from GitHub at scale: we extended the Boa framework to parse Python using ANTLR grammars for Python 2 and 3, transformed the source into ASTs stored in Boa’s Protobuf format, and hosted the result on a Hadoop cluster where Boa’s domain-specific language runs automatically parallelized queries. The resulting dataset covered 1,558 mature, top-rated data science projects — about 5 million Python file snapshots across all revisions — and was later extended to parse Jupyter notebooks.
Building on this infrastructure, we studied the architecture of data science pipelines: the stages such as data acquisition, preprocessing, modeling, training, and evaluation through which data flows in data-driven software. We conducted a three-pronged study of pipelines in theory, in-the-small, and in-the-large to characterize their typical stages, connections, and feedback loops, and to give pipeline architects representative structures to compare against. This work was supported in part by the NSF TRIPODS institute D4 (Dependable Data-Driven Discovery).
Key Results
- Released the first open dataset for studying Python data science software (MSR 2019), containing 1,558 GitHub projects selected by filtering for original Python projects with at least 80 stars, data science keywords in the description, and usage of at least one of 33 data science libraries.
- The dataset spans 350 organization-maintained projects (including Google, Microsoft, and NVIDIA) and 1,208 individually maintained projects, and is publicly queryable through the Boa infrastructure both as raw projects and in processed AST form.
- Conducted a three-pronged study (ICSE 2022) of 71 pipeline proposals from the literature, over 105 curated Kaggle pipeline implementations, and 21 mature GitHub projects, producing three representative pipeline structures for data science in theory, in-the-small, and in-the-large.
- Found that small data science programs omit stages present in theory and lack clear stage separation, while large projects build complex pipelines with feedback loops, sub-pipelines, and strict stage boundaries needed for scalability, maintenance, and testing.
Related Publications