ML Software Maintenance and Technical Debt
We study how technical debt appears and evolves in machine learning software, mining self-admitted technical debt at scale to guide the maintenance of ML systems.
People: Sumon Biswas, David O'Brien, Sayem Imtiaz, Rabe Abdalkareem, Emad Shihab, Hridesh Rajan
Overview
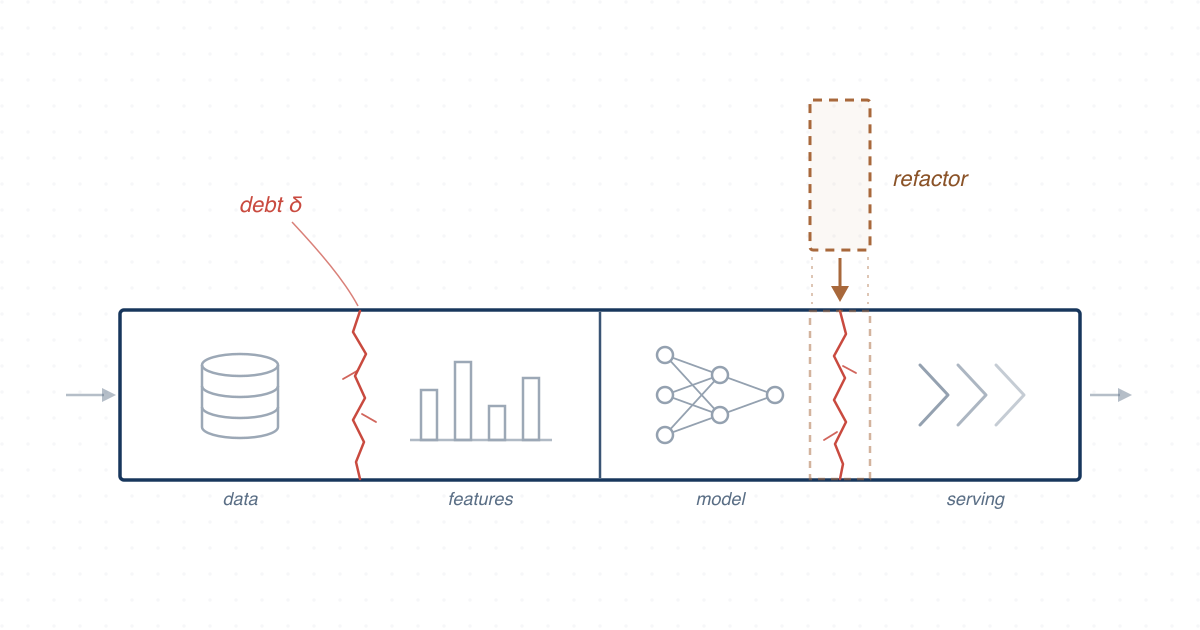
ML software has distinctive maintenance risks because data, models, pipelines, and code evolve together. Technical debt can infect the data that models are trained on, degrading the functional performance of ML systems in ways traditional debt does not, and the growing inclusion of ML components in modern software introduces new kinds of debt.
We study how this debt appears in ML repositories in the wild. Mining 68,821 self-admitted technical debts (SATDs) from all revisions of 2,686 mature ML repositories on GitHub, we build taxonomies of ML-specific debt, locate the pipeline stages where it accumulates, and track how it is introduced and removed — evidence developers and researchers can use to build maintainable ML systems.
Current Focus
- A taxonomy of 23 types of self-admitted technical debt in ML software, derived through open coding of 68,821 SATDs from 2,686 mature GitHub repositories (FSE 2022)
- Locating where ML SATDs occur across the stages of the ML pipeline and how their frequencies differ between those stages
- Contrasting the debts found in ML applications with those in ML tools, and measuring the effort required to remove ML SATDs
- Repository-mining infrastructure for studying ML and data-science software at scale
Related Publications