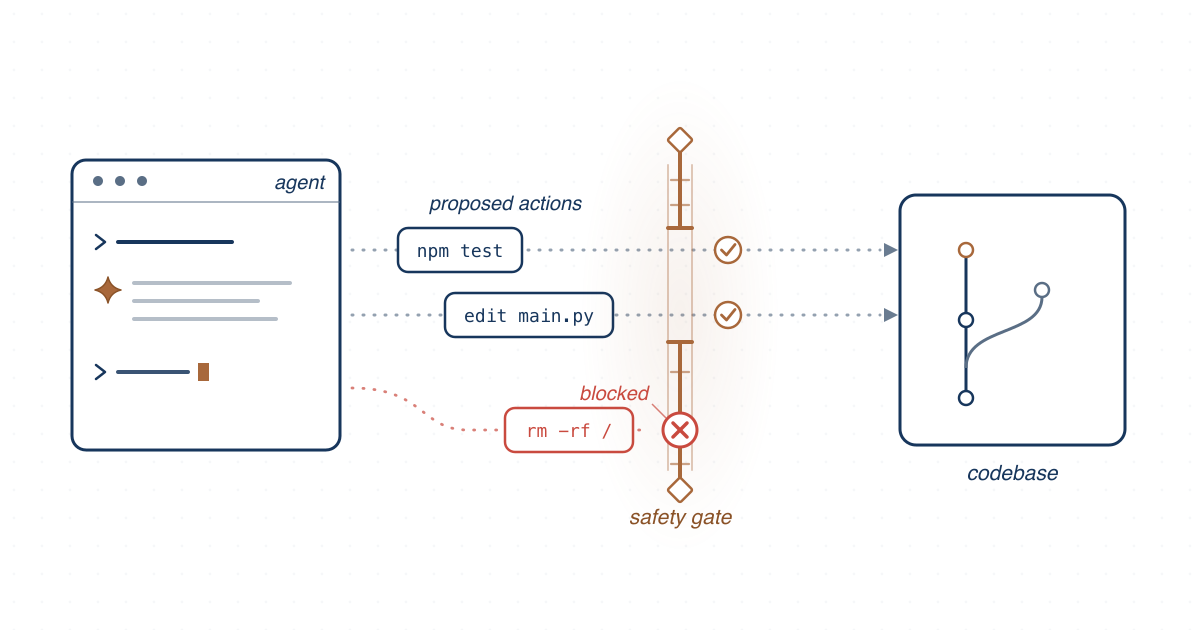
We study how autonomous coding agents fail during ordinary development work and design safeguards, from constraint enforcement to failure transparency and safe-halt behaviors, for deploying them responsibly.
Research
Designing responsible AI-enabled software systems.
The reSAID Lab builds the methods, tools, and empirical understanding needed to engineer AI-enabled software that is reliable, fair, safe, and maintainable. Our work spans the full lifecycle of AI software — from how large language models reason and generate code, to how ML components are specified, verified, tested, and maintained in real systems. The themes below describe the questions we focus on; the projects that follow show how we pursue them, and each links to the publications it produced.
Research Themes
We work at the intersection of software engineering and artificial intelligence, with an emphasis on building responsible, trustworthy AI systems.
Responsible AI Engineering
Designing, building, and evaluating AI systems that are fair, safe, reliable, accountable, and aligned with human values. We develop methods for verifying, testing, and auditing AI software throughout the engineering lifecycle—spanning long-term fairness under feedback loops, compositional fairness in pipelines, and trustworthy system design.
LLMs and Coding Agents
Studying how large language models reason, plan, and generate code. We investigate LLM reasoning capabilities, coding agent reliability, bias in LLM outputs, and the technical debt that arises when LLMs are used in software development.
Formal Verification and Program Analysis
Applying formal methods, static and dynamic program analysis, and verification techniques to reason about correctness, safety, and fairness properties of software and ML-enabled systems. We build tools that provide provable guarantees and detect defects in AI software.
Software Engineering for AI
Applying software engineering principles—architecture, testing, maintenance, and quality—to AI and ML systems. We study data science pipelines, ML system architecture, and engineering practices for AI-enabled software.
Projects
Active and recent projects, organized by topic. Each project links to the papers behind it.
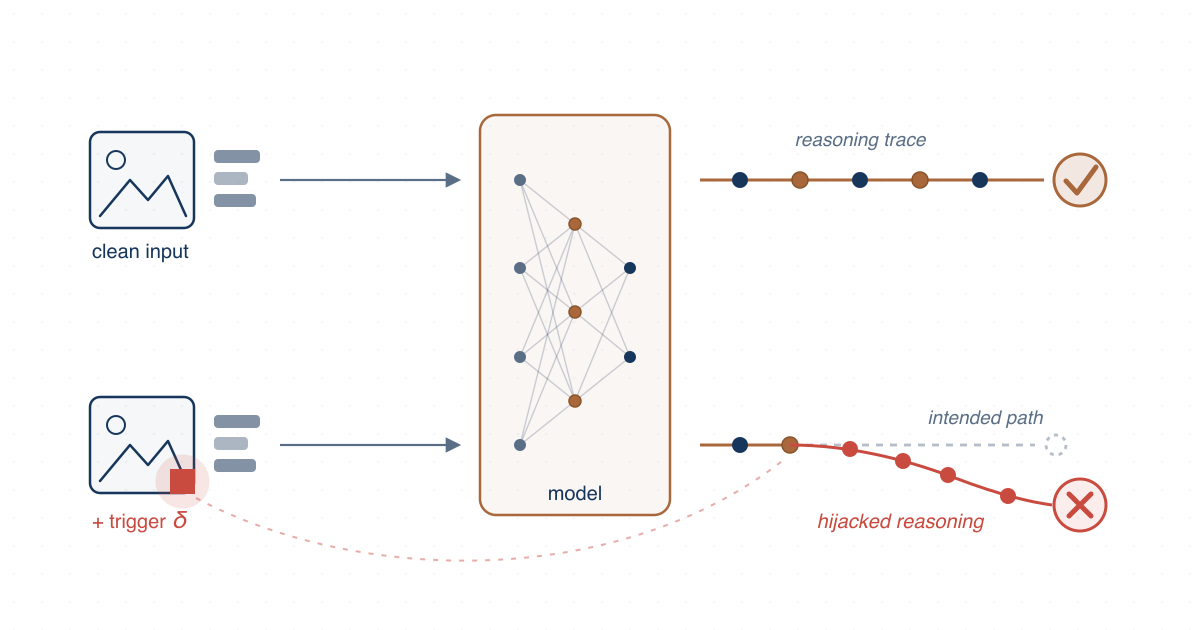
Testing and analysis for hidden failure modes in large language and vision-language models, from social bias under black-box access to reasoning-level backdoors.
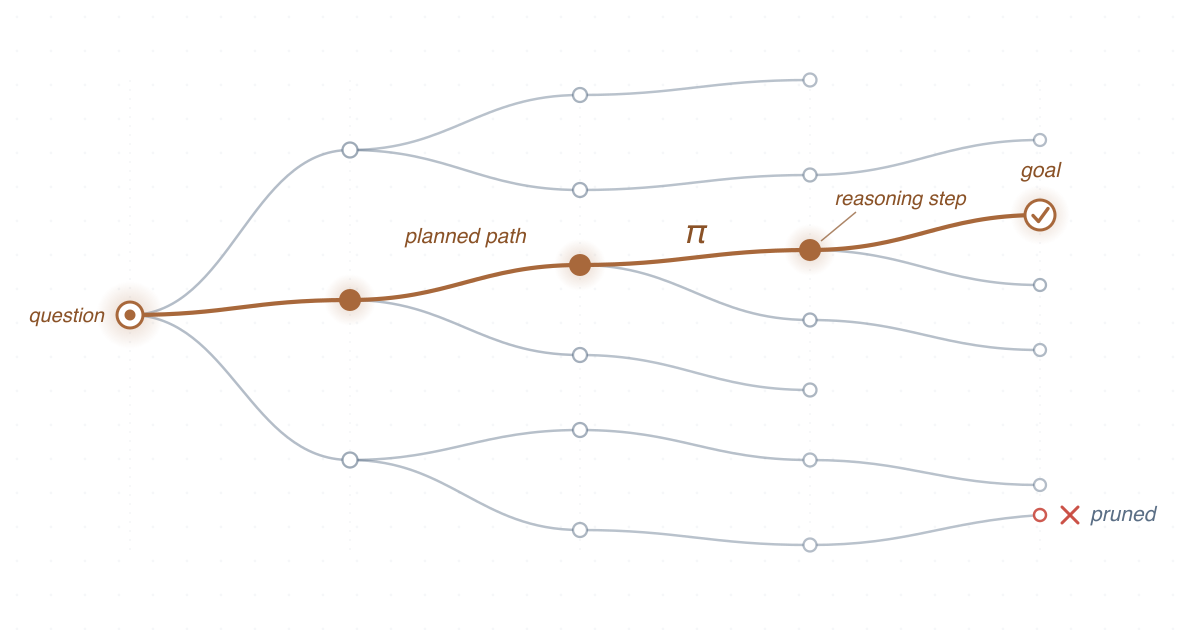
Methods that make language-model reasoning more deliberate, structured, and inspectable, separating high-level planning from low-level action generation.
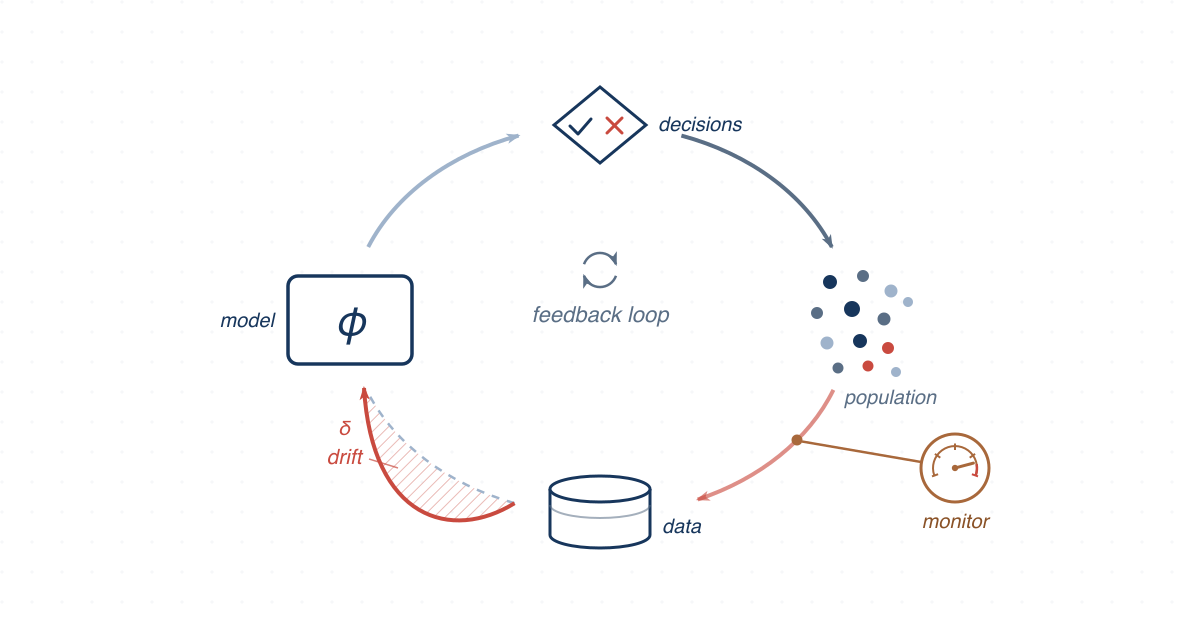
Simulation-based analysis of long-term fairness and safety in ML-enabled systems whose decisions reshape their own future inputs through feedback loops.
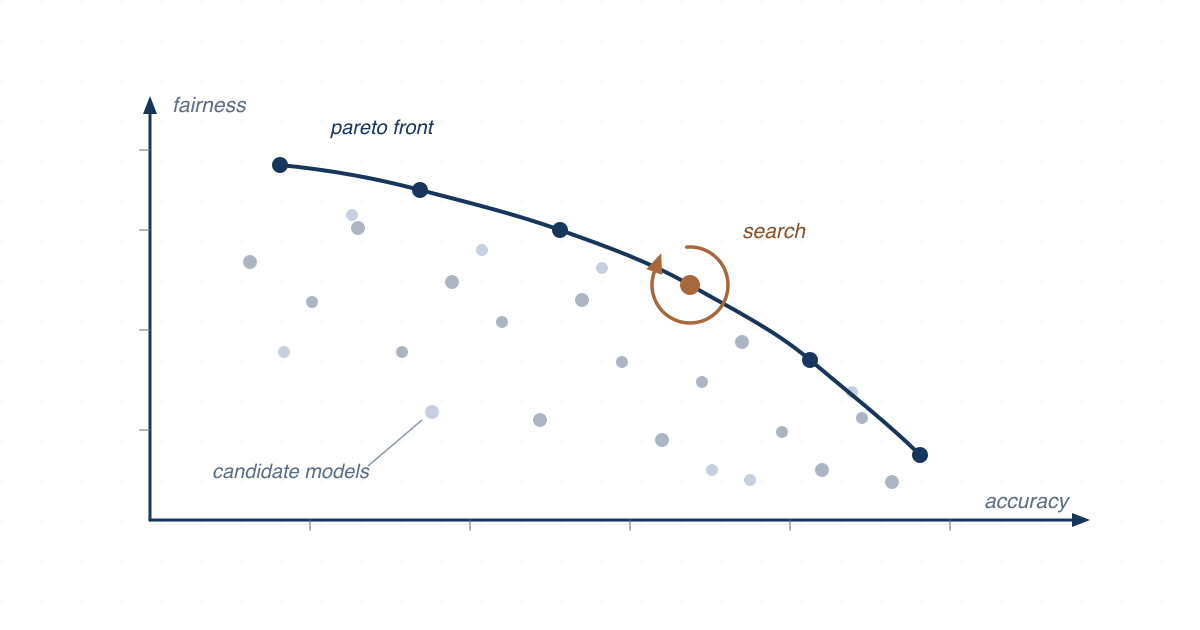
We repaired unfair ML models using AutoML with a fairness-aware optimization function and search space, mitigating bias with little to no loss of accuracy.
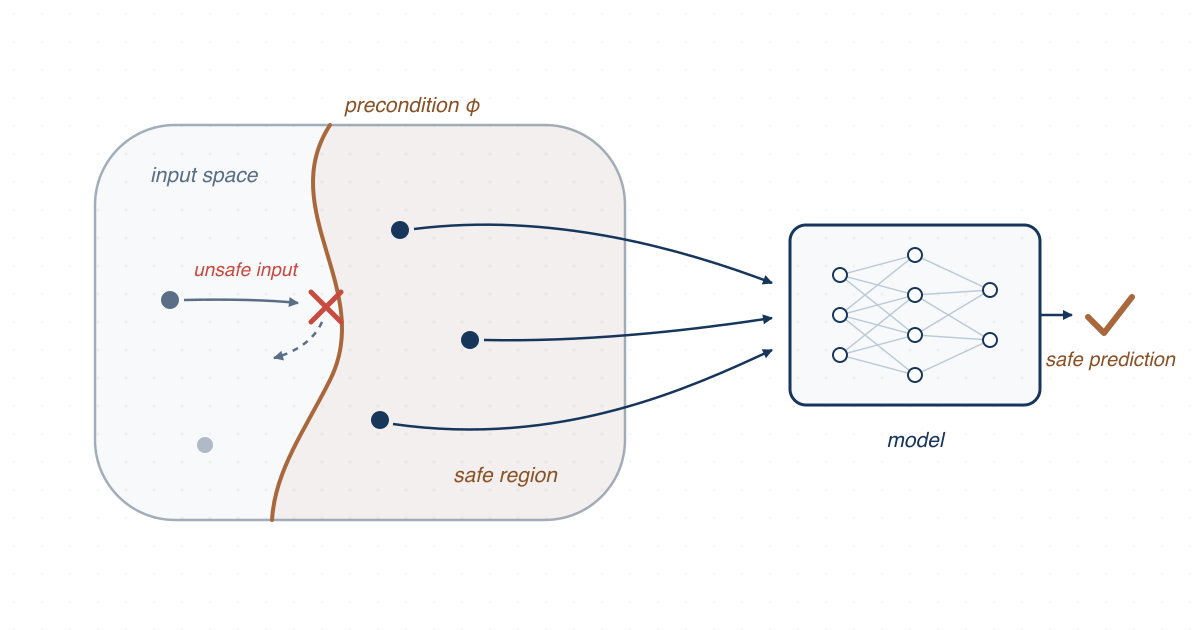
We provided safety assurance for ML-enabled systems by inferring preconditions over pipeline abstractions and identifying safety risks from feedback loops between the system and its environment.
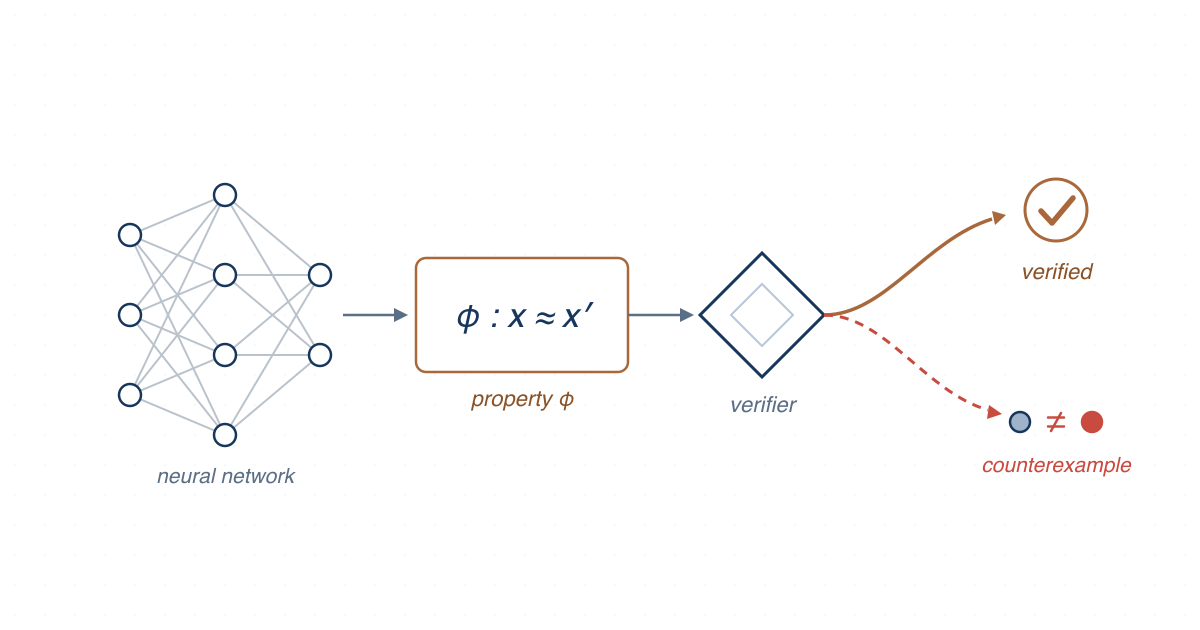
SMT-based verification of individual fairness in neural networks, using input partitioning and sound neural pruning to produce certificates or counterexamples for real-world models.
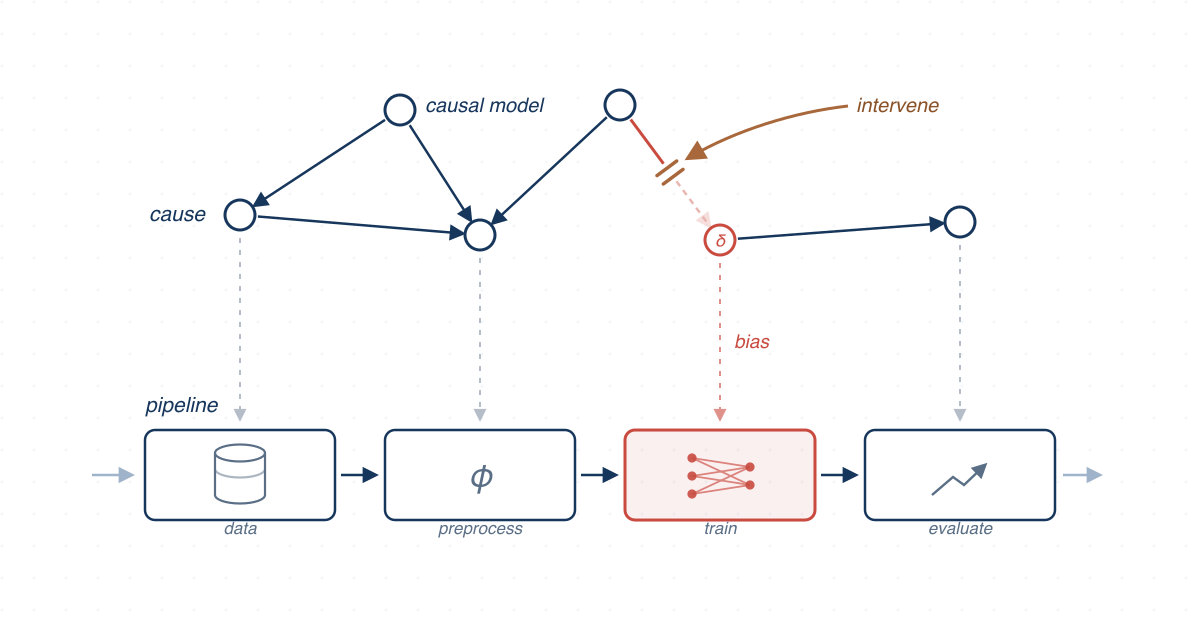
We used causal reasoning to measure the fairness of individual stages in machine learning pipelines and studied how fairness composes across preprocessing, ensembles, and real-world models.
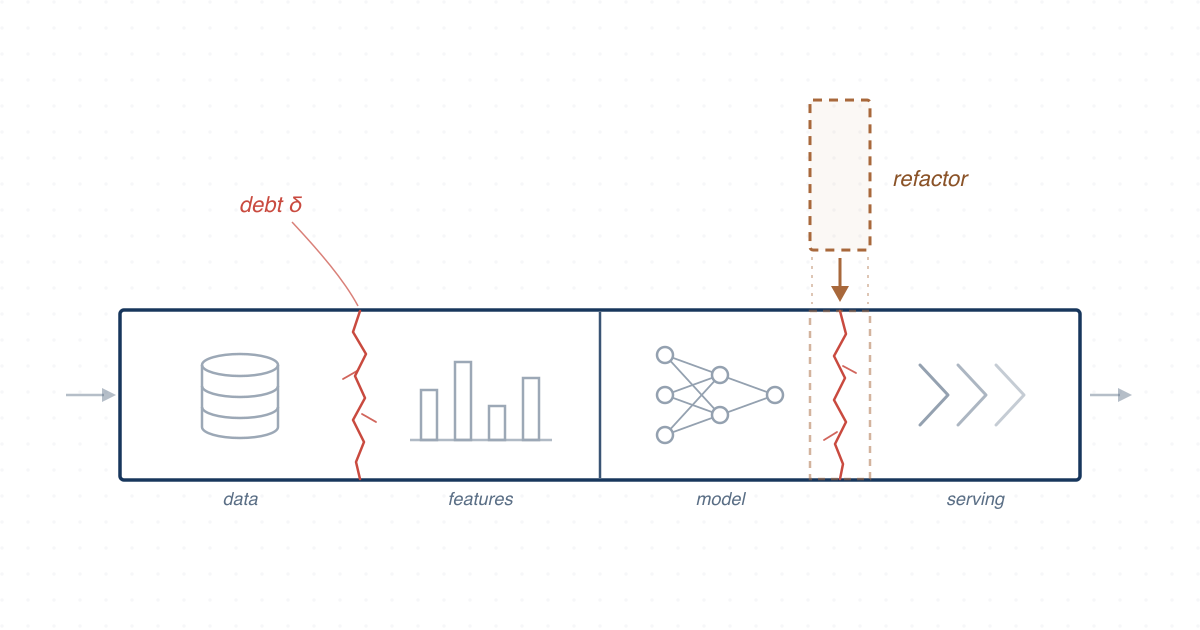
We study how technical debt appears and evolves in machine learning software, mining self-admitted technical debt at scale to guide the maintenance of ML systems.
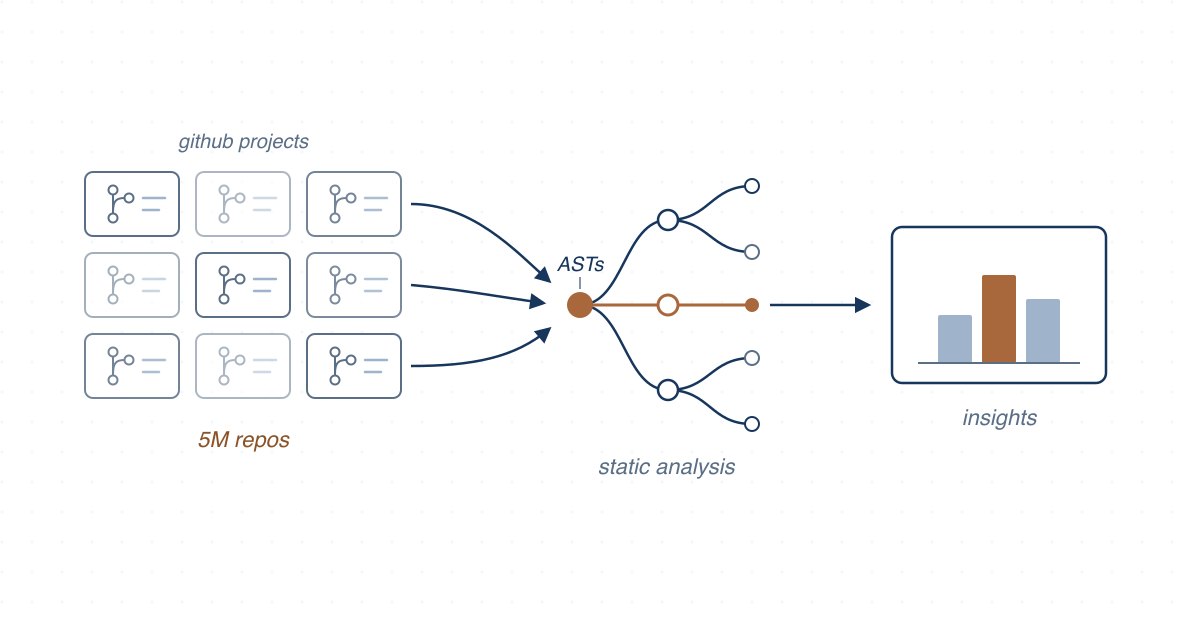
We built infrastructure to mine millions of Python data science programs from GitHub and studied how data science pipelines are structured in theory, in-the-small, and in-the-large.